C언어 샘플코드 - 파일입출력과 문자열 파싱

2년도 전에 타 블로거의 글을 참고해서 문자열함수에 대해 공유 드린적이 있었습니다.
( http://ironmask.net/198 )
내가 아닌 다른 분이 작성한 것을 참고하는 것은 역시 세월이 지나면,
참고할 때의 기억이 잘 안나는 것 같네요 ㅎㅎ
SW개발 업무를 맡고는 있지만 디버깅하는 업무가 많다보니,
코딩을 할 때 원하는 함수나 문법이 생각이 나지 않을 때가 종종 있습니다.
사실 다루는 프로그래밍 언어도 한 개에 국한되지 않으므로 더욱 혼잡함 ㅜㅜ
아무튼 그래서 기회되는 대로 샘플코드 형식으로 기록도 남기고,
방문자분들에게도 좋은 정보를 제공하도록 하겠습니다. :)
주제 요약 설명
C언어로 파일을 읽어와서,
특정 키워드와 비교하는 조건문을 통해,
특정 delimiter로 파싱해서 결과물을 얻는 코드 입니다.
주요 사용 함수는 fopen, fgets, strncmp, strtok 입니다.
C언어의 기본 문법과 함수에 대한 사용법을 어느 정도 숙지하신 것을
기본 전제로 진행합니다. ^^
샘플 코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 | #include <stdio.h> #include <stdlib.h> #include <string.h> /* Start 2017-10-10 By ironmask */ int main( int argc, char* argv[] ) { char* token; char* token2; char strline[100]; // one line sentence int i = 0; char* word = "iface eth0 inet static"; // keyword FILE *fp = fopen("../../etc/network/interfaces", "r+"); if(fp == NULL){ puts("FAIL"); return -1; } while(fgets(strline, sizeof(strline), fp)) // 한줄을 읽는데 size 만큼 읽는다. { // interfaces File 내에 특정 키워드 찾기 if(strncmp(strline, word, strlen(word) ) == 0) { // address fgets(strline, sizeof(strline), fp); token = strtok(strline, " "); // 공백을 delimiter 기준으로 자르기 token = strtok(NULL, " "); // 더 이상 문자열이 없으면 NULL을 반환 token[strlen(token)-1] = '\0'; // gets 함수는 마지막에 \n이 들어가므로 이를 제거하기 위해 널값 삽입 printf("%s\n", token); // netmask fgets(strline, sizeof(strline), fp); token = strtok(strline, " "); token = strtok(NULL, " "); token[strlen(token)-1] = '\0'; printf("%s\n", token); // broadcast fgets(strline, sizeof(strline), fp); token = strtok(strline, " "); token = strtok(NULL, " "); token[strlen(token)-1] = '\0'; printf("%s\n", token); // network fgets(strline, sizeof(strline), fp); token = strtok(strline, " "); token = strtok(NULL, " "); token[strlen(token)-1] = '\0'; printf("%s\n", token); /* token2 = strtok(token, "."); printf("%s\n", token2); token2 = strtok(NULL, "."); printf("%s\n", token2); token2 = strtok(NULL, "."); printf("%s\n", token2); token2 = strtok(NULL, "."); printf("%s\n", token2); */ } // memset( &strline, 0, sizeof(strline) ); // printf("hello\n"); } fclose(fp); return 0 ; } | cs |
아래는 위 소스에서 사용된 interfaces 파일 내용 입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | # /etc/network/interfaces -- configuration file for ifup(8), ifdown(8) # The loopback interface auto lo iface lo inet loopback # Wireless interfaces iface wlan0 inet dhcp wireless_mode managed wireless_essid any wpa-driver wext wpa-conf /etc/wpa_supplicant.conf iface atml0 inet dhcp # Wired or wireless interfaces allow-hotplug eth0 auto eth0 iface eth0 inet static address 192.168.0.1 netmask 255.255.255.0 broadcast 192.168.0.255 network 192.168.0.0 up /etc/network/if-up.d/eth0-up.sh allow-hotplug eth1 auto eth1 iface eth1 inet static address 10.104.91.15 netmask 255.255.255.0 network 10.104.91.0 gateway 10.104.91.1 dns-nameserver 156.147.19.132 up /etc/network/if-up.d/eth1-up-nat.sh down /etc/network/if-post-down.d/eth1-down-nat.sh | cs |

'컴퓨터공학 > C언어 레퍼런스' 카테고리의 다른 글
| C언어 정리하기 - 문자열과 문자열 함수 (0) | 2015.04.08 |
|---|---|
| C언어 강좌 문자열 배열과 null (2) | 2015.04.03 |
| C언어 정리하기 - 자료형이 곧 핵심 (0) | 2015.04.01 |
| Sprintf 함수 (0) | 2010.11.24 |




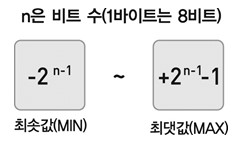

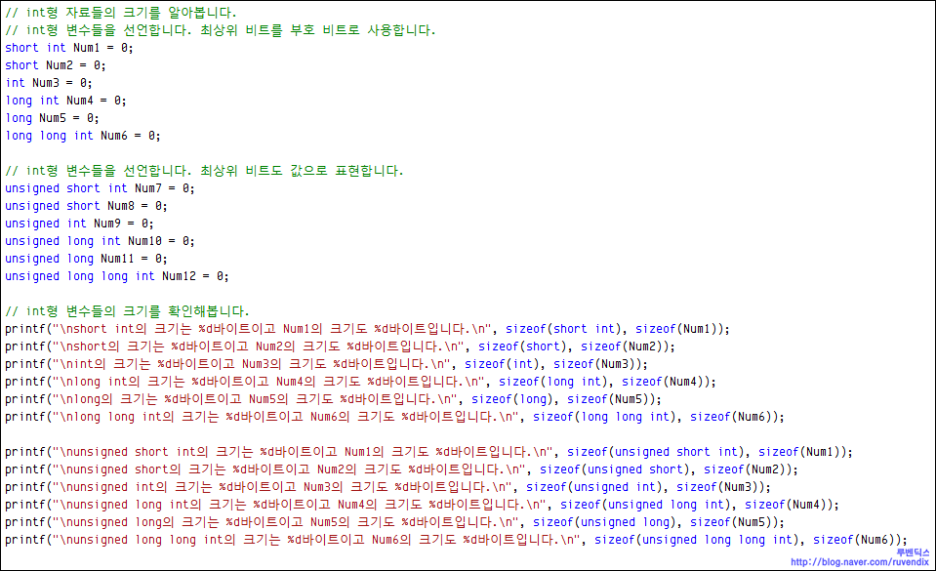
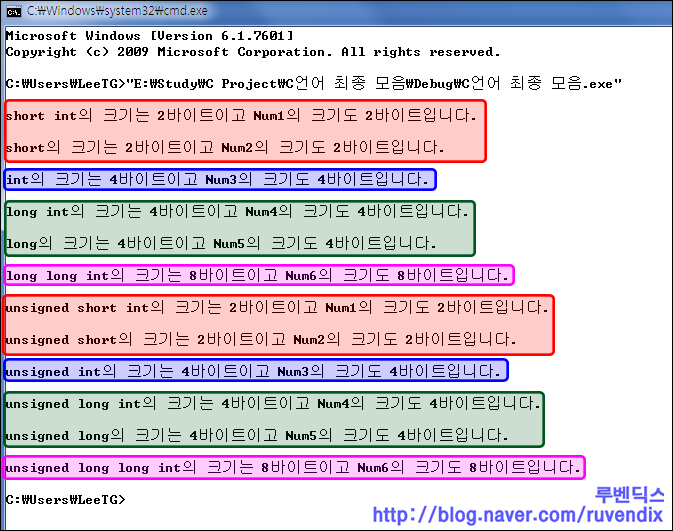 ?
?




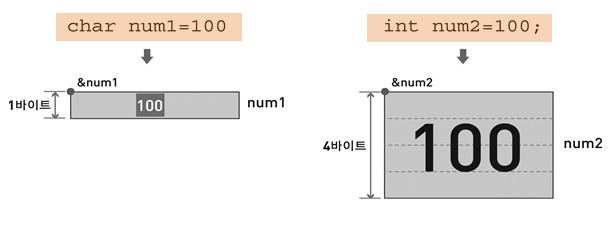

 ?
?



 ?
?






 ?
?




