아래 자료 출처 : http://ruvendix.blog.me/220263134254

오~ 드디어 자료형까지 왔네요. 그런데 여기서부터 변화를줄까 합니다.
제가 설명은 최대한 쉽게하고 있으나 너무 길어진다는 단점이 생겨서...
아예 확 줄여버릴까 해요.
너무 길면 보는 사람들도 지루해하고 제가봐도 좀 짜증나더라고요...
이제는 글보다는 그림으로~ 긴 설명은 죄다 요약글을 활용할게요.
?아무리 길어도 그림만 넘치면 지루하지는 않겠죠?
그래서 강의 자료의 도움을 받을게요.
원래 무료로 제공하는 강의 자료고 제가 뭐 돈 주고 판다던가 그런것도 아니고...
뭔가 그럴듯한 그림이라면 다 프리렉의 저작권이라고 보시면 됩니다.
강의 자료를 사용하는게 문제가 된다면 댓글로 알려주세요~

와... 하고싶은 말만 했는데도 벌써 길어지네요? 이제 시작할게요.
[자료형(Data Type)]은 모든 프로그래밍 언어에서 사용해요.
왜 그럴까요? 자료형은 컴파일러가 정보를 메모리에 저장하거나 가져올때 유용하기 때문입니다.
집을 짓는데 주택인지 아파트인지 오피스텔인지 이렇게 구분하는거에요~
만약 구분을 하지 않는다면? 집이 어떤 형태의 집인지 알 수가 없겠네요...
자료형은 변수에만 해당되는게 아니라 함수에도 해당이 됩니다.
근데 뭐... 함수는 아직 설명할때가 아니므로 변수만 설명할게요.
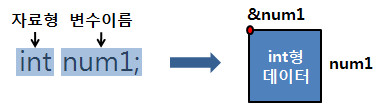
그동안 포스팅을 진행하면서 몇 번 얘기했었지만 변수는 형식이 있어요.
변수를 만들때는 [자료형 | 변수의 이름 | 변수의 값] 이렇게 만든답니다.
이걸 비유하자면 "집의 종류, 집의 이름, 집에서 사는 사람" 이렇게 되겠네요.
"&"는 주소 연산자로 변수나 함수가 시작되는 위치를 알려줍니다.

자료형은 크게 고정 소수점 수 자료형과 부동 소수점 수 자료형이 있어요~

너무 어려운 말이죠?
컴퓨터는 2가지의 자료형만 아는데 [정수형 자료형]과 [실수형 자료형]으로 구분해요.
?이제 정수형 자료형부터 알아볼건데 이번 포스팅에서는 알면 좋은 정보가 있어요.?
자료형에 대한 설명을 봤던 분들이라면 잘 아시겠지만 자료형은 크기가 중요합니다.
주택과 아파트는 크기가 다르죠? 보통 아파트가 건물이 더 큽니다.
그리고 그 크기를 이용해서 최댓값과 최솟값을 알 수 있어요~ 아파트가 1층부터 몇 층까지 있는지 알 수 있듯이요.
C언어에서는 명령어 [sizeof()]를 사용하면 자료형의 크기를 알 수 있습니다.?
"()" 여기 안에 자료형이나 변수를 넣으면 크기를 바이트로 알려줘요.
그리고 그 바이트를 이용해서 최솟값과 최댓값을 알아낼 수 있습니다.
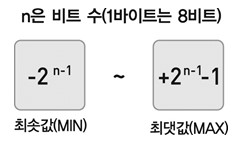
위의 이미저처럼 최솟값과 최댓값을 계산하는데 비트로 계산해요. 1바이트는 8비트입니다.
4바이트의 자료형의 최솟값과 최댓값을 구해보면 이렇게 되겠네요.?
-231 ~ +231 - 1?
즉, -2147483648 ~ 2147483647이 되겠네요~ 왜 저런 공식이 나왔을까요??
공식을 적용하면 바이트를 이용해서 최솟값과 최댓값을 구할 수 있겠죠?
정말 많이 사용하니까 잘 알아두세요~ 자료형의 크기를 알려면 [sizeof()]를 사용해야 합니다.
함수가 아니라 C언어의 명령어니까 헷갈리지 않도록해요~
그런데 최솟값과 최댓값의 범위를 넘어가면 어떻게 되는걸까요? 최상위 비트는 고정이므로 변하지는 않을테고...
최솟값의 범위보다 내려가는걸 [언더 플로우(Under Flow)]라 하고
최댓값의 범위보다 올라가는걸 [오버 플로우(Over Flow)]라 합니다.
자료형을 사용하면서 정말~ 많이 발생하는 오류니까 잘 알아두세요!
이제 자료형을 하나씩 알아볼건데 int형부터 알아볼거에요.

int형은 가장 많이 사용하는 자료형으로 종류도 다양합니다.
int형은 보통 [short, int, long, long long]으로 사용하고 여기에 [unsigned]를 조합한 형태로 많이 사용해요.
컴파일러가 알아서 판단하기는 하지만 원래는 short int, int, long int, long long int로 써야 맞습니다.
생략하기보다는 직접 다 써보는게 아마 더 도움이 될거에요~
최솟값과 최댓값을 알아내기 위해 몇 바이트인지 알아볼게요.
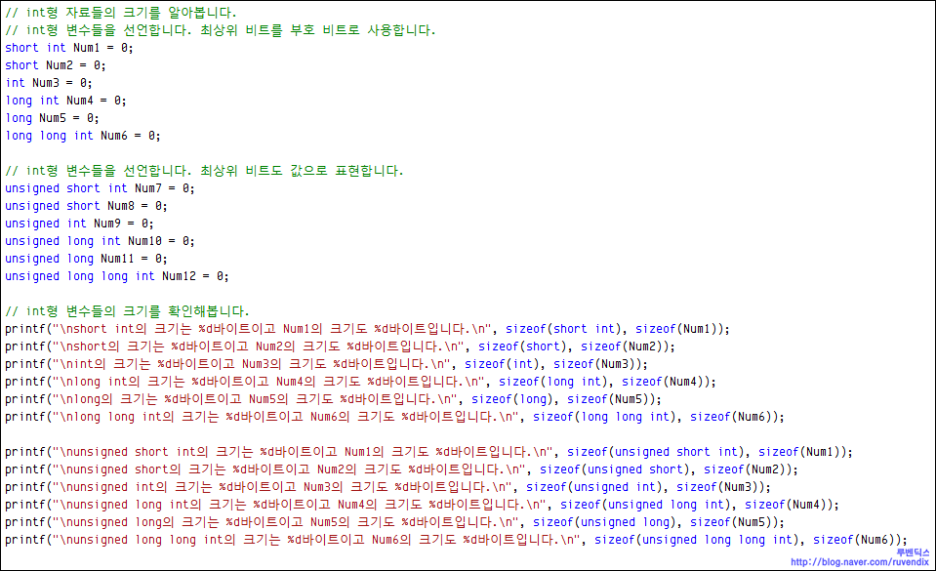
소스 코드가 슬슬 복잡해지네요... 천천히 읽어보세요...
?sizeof()를 잘 활용해야 합니다. 자료형을 넣어도 되고 변수를 넣어도되요~
 ?
?
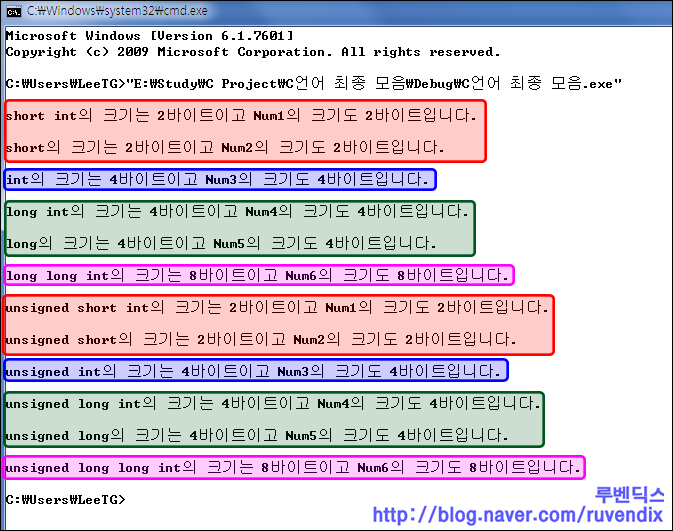
?알록달록 하네요~ 각 크기를 알아본건데 short int나 short나 둘 다 2바이트죠? 같은 자료형입니다.
가장 큰 자료형은 long long int로 8바이트나 되네요.
그런데 int는 원래 4바이트가 아니였어요. 컴퓨터 시스템이 발전하면서 크기가 커진것이지요.
C언어는 약 40년동안 계속 업데이트되고 새로 생긴것도 많아요. scanf_s() 함수가 그런거지요.
그래서 이건 보고싶은 분들만 보세요~
int 자료형들의 바이트를 알았으니 최솟값과 최댓값을 알 수 있겠네요.
그런데 이걸 굳이 계산 안해도 C언어에서 매크로 상수로 제공해줍니다.

"limits.h"? 헤더 파일은 int 자료형의 최솟값과 최댓값을 매크로 상수로 제공해줘요.

각 매크로 상수의 이름들이 보이죠? int 자료형들과 비교해보세요~
"%u"는 unsinged 자료형의 값을 제대로 출력하기 위해서 사용하는 형식 문자입니다.
"%lld"는 long long int를 출력할때 사용해요. 나중에 만들어진 자료형은 형식문자가 따로 있어요.
"%llu"는 unsigned long long int를 출력할때 사용합니다.

?4바이트와 8바이트의 엄청난 값 차이...
unsinged long long int의 최댓값은 1844경...

?
?char 자료형은 문자를 표현하기 위해 만든 자료형입니다.
ASCII로 문자를 표현할때는 7비트만 사용하고 나머지 하나의 비트는 패리티 비트로 사용해요.
그러니 굳이 int처럼 4바이트로 만들 이유가 없죠? char 자료형은 1바이트 입니다.
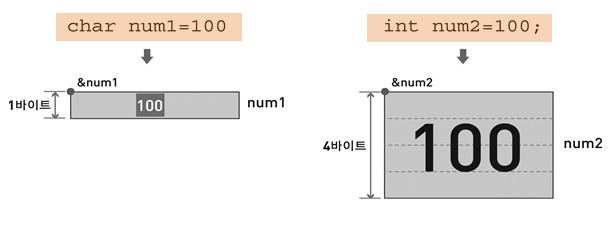
char는 1바이트니까 메모리에서 한 칸을 차지하고
int는 4바이트니까 메모리에서 4칸을 차지합니다.
실제로 숫자가 저렇게 들어가는건 아니므로 오해하면 안돼요~
컴퓨터는 문자도 다 숫자로 인식합니다. 이 얘기만 몇 번째야...
컴퓨터가 문자를 숫자로 인식하는 방법이 참 여러가지인데 ASCII가 그 중 하나입니다.
ASCII는 영어와 일부 특수 문자들을 1바이트로 만든건데 개수도 255개인가 그래요.
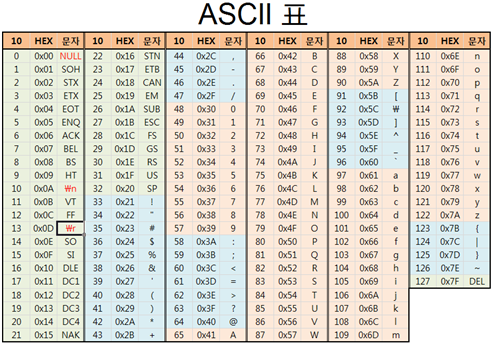
ASCII 표를 보면 영어 대문자가 65부터 90까지고 영어 소문자가 97부터 122까지네요.
약간 헷갈릴 수 있는게 ASCII는 영어를 1바이트로 표현하지만 유니코드는 2바이트로 표현해요.
ASCII나 유니코드 같은걸 문자 집합(Character Set)이라 하는데 이건 나중에 설명할게요.

char에 그냥 숫자를 넣어도 되고 작은 따옴표('')를 사용해서 넣어도 됩니다.
단! char 자료형은 1바이트이므로 문자 하나만 인식할 수 있어요.
그리고 큰 따옴표("")는 사용할 수 없답니다.
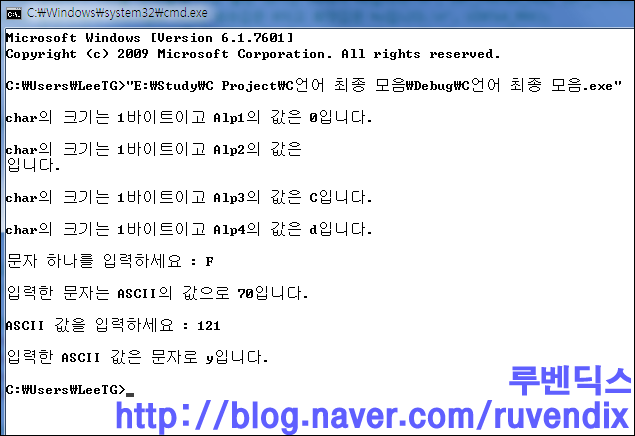 ?
?
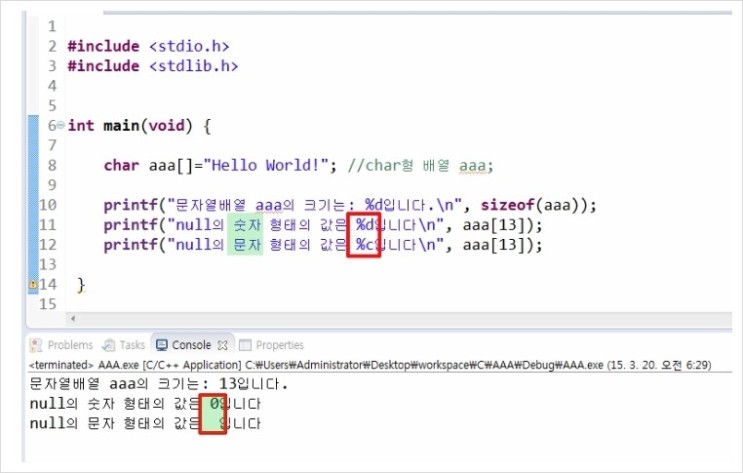
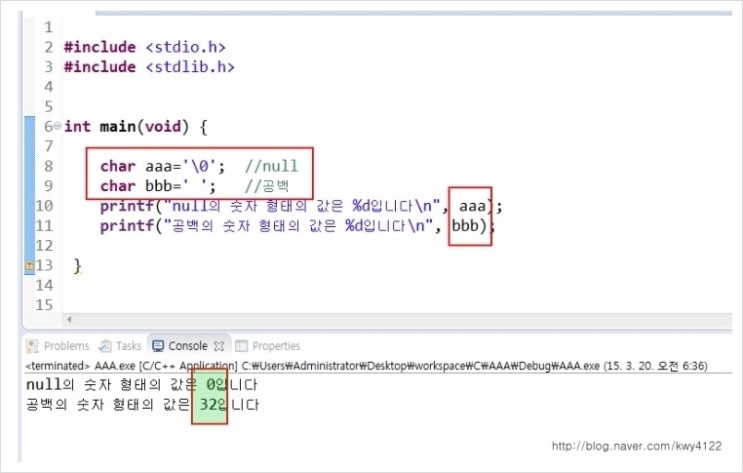
첫 번째 출력 결과는 10에서 1이 짤리고 0만 출력되었네요.
두 번째 출력 결과는 ASCII로 10이 "\n"이므로 다음 줄로 갔군요.
문자를 입력하면 ASCII로 바꿀 수 있고 ASCII를 입력하면 문자로 바꿀 수 있어요.

?float 자료형은 int 자료형보다 보다 더 정확한 값이 필요할때 사용해요.
int 자료형만큼 종류가 많지도 않고 굉장히 간단합니다.
[float, double, long double] 이렇게 3개만 있어요. unsigned는 없답니다.
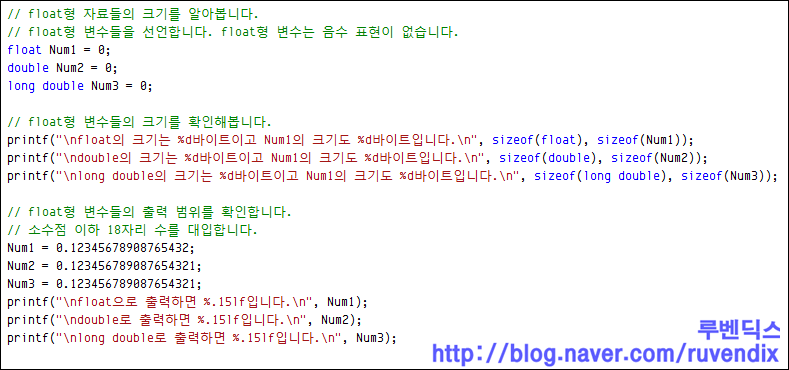
?float 자료형은 소수점마다 출력 범위가 다른데 float은 소수점 이하 6번째 자리까지 제대로 출력합니다.
double이나 long double은 같은 자료형이에요. 소수점 이하 15번째 자리까지 제대로 출력합니다.

?0.12345678908765432이라는 소수점 17자리 수를 출력하면 float은 0.123456까지 제대로 나옵니다.
0.1234567까지 나오는데요? 제대로 나온게 아니라 숫자가 말린겁니다.
double이나 long double은 0.123456789087654까지 제대로 나옵니다.
?바이트를 알았으니 float 자료형의 최솟값과 최댓값을 알아보죠.

?float 자료형의 최솟값과 최댓값은 "float.h" 헤더 파일에 매크로 상수로 있습니다.

소스 코드를 보면 매크로 상수를 알 수 있을거에요.
 ?
?
?float 자료형의 최솟값과 최댓값은 뭔가 환상적이네요?
아니 8바이트인데 뭐가 이렇게 복잡하게 나오는걸까요?
고정 소수점 수와 부동 소수점 수의 차이입니다.?
숫자의 범위가 워낙 크기 때문에 "%lf"로는 출력이 어려워요.
그래서 지수 표현으로 출력하는 "%le"를 사용합니다.?
int 자료형과 char 자료형 그리고 float 자료형을 알아봤어요.
그런데 각 자료형은 서로 섞일 수도 있고 다른 자료형으로 바꿀 수도 있습니다.
자료형을 섞으면 보통 바이트가 큰 자료형으로 합쳐져요.
int 자료형과 float 자료형을 섞으면 float 자료형이 됩니다.
char 자료형과 int 자료형을 섞으면 int 자료형이 되고요.
이렇게 섞는거 말고 자료형을 바꿀 수도 있는데 2가지의 경우가 있어요.
하나는 컴파일러가 알아서 바꾸는 [자동 형변환(Auto Type Casting)]이 있고
사용자가 자료형을 바꾸는 [강제 형변환(Coercion Type Casting)]이 있습니다.
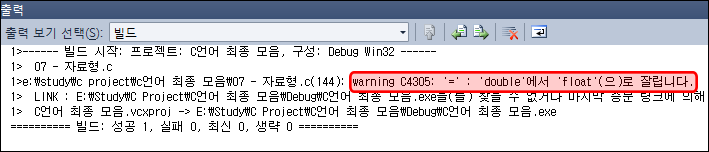
?자동 형변환은 이렇게 컴파일러가 자료형을 막 바꿉니다.
컴파일러는 기본적으로 실수를 double로 보는데 사용자가 float으로 선언하면 잘라버립니다.
그래서 float은 값이 제대로 나올때도 있고 아닐때도 있어요...

강제 형변환은 이렇게 사용자가 직접 자료형을 바꿉니다.
"()" 안에 바꾸고싶은 자료형을 입력하면 자료형이 변해요.

int 자료형과 double 자료형을섞는 소스 코드입니다.
double 자료형을 제대로 출력하려면 "%lf"를 써야해요.

?int 자료형과 double 자료형을 더하면 double이 되네요.
int 자료형끼리 연산하면 int 자료형이 되지만~
강제 형변환으로 double로 바꾸면 double 자료형으로 값이 바뀝니다.

C언어에서는 사용자가 직접 자료형을 만들기도 합니다.
정확히 말하자면 원래있던 자료형을 이용해서 이름을 바꾸는거지요.

??typedef는 Type Definition의 줄임말입니다.
typedef를 쓰고 기존 자료형을 쓰고 새로운 이름을 쓰는건데 이걸 왜 쓰는걸까요?
기존 자료형을 두는게 더 좋은거 아닌가요? 맞는 말이긴 하지만 아닌 경우도 있어요.

?unsigned long long int 같은 경우는 기존 자료형이지만 무지 깁니다.
그래서 typedef를 사용하면 이걸 확~ 줄일 수 있어요.
unsigned long long int를 ULLINT로 새롭게 만들면 줄어들겠죠?
?typedef를 사용하면 뭐가 뭔지 모르는 경우가 있는데 그러면 자료형에 마우스를 올려보세요.
빨간색으로 표시한 것처럼 어떻게 만들어진 자료형인지 알려준답니다.
 ?
?
unsigned long long int나 ULLINT나 둘 다 똑같은 자료형입니다.
둘 다 8바이트의 자료형이라는걸 확인할 수 있죠??
여기까지~ 자료형에 관한 포스팅이였습니다.
포스팅 방식을 좀 새롭게 바꾸니까 평소보다 짧아진 느낌이 들죠?
다음 포스팅에서는 C언어의 꽃이자 프로그래밍 언어의 꽃인 반복문을 설명할게요.


 vc_web.exe
vc_web.exe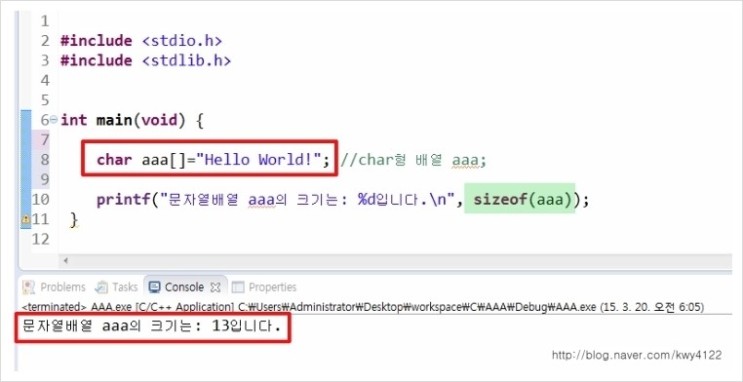
.jpg)
.jpg)
.jpg)
.jpg)


