[비상금통장] cma에 대하여
cma 통장, 알기 어려운 영어 이름이지만, 많은 분들이 너무 자주 들어서 익숙해졌을 겁니다^^
cma 통장은 Cash Management Account의 줄임말 입니다.
우리 말로 하면 현금 관리 통장이라고 해석이 되는데요..
통장의 특성상 현금 처럼 아무때나 꺼내서 쓸 수 있는 것이 장점이며
하루만 맡겨도 3~4.0%의 시중금리가 이자로 붙어서 비상금 통장에 제격입니다.
오늘 글에서는 비상금 통장에 사용하면 딱, 좋은 cma 통장에 대해서..
금리비교부터 추천 상품들까지 살펴보겠습니다.

내용을 읽기에 앞서 비상금통장을 왜 만들어야 하는지?
통장쪼개기와 현금흐름 자산관리는 어떻게 준비해야 하는지?
..에 대해서 먼저 읽을 글이 있으니 내용 파악을 하고 본문을 읽어보세요.
※ 먼저 읽을 글
통장쪼개기 part 1. 급여통장, 지출통장
통장쪼개기 part 4. 비상금통장 활용방법
위의 글을 읽어보면.. cma 통장이 급여통장이나 지출통장 보다
비상금 통장에 더 적합하다는 것. 알 수 있을텐데요.
cma 통장을 급여통장으로 사용하기가 꺼려지는 이유는
1. 은행과의 거래를 포기해야 하므로 주거래은행과의 실적이 아쉬워진다.
2. 통장쪼개기를 잘 실천할 경우 cma의 고금리 혜택을 받을 일이 거의 없기 때문입니다.
그리고 지출통장은.. 은행 계좌에 연결된 체크카드를 사용하는 것이
변동지출 통제에 효과적이니 cma통장을 고민할 필요가 없을테지요.
그리고 은행의 수시입출금 통장도 언제든지 돈을 넣고 뺄수 있다는 점에서는 마찬가지입니다만,
이자가 연 1%도 채 되지 않지요. 그러나 cma 통장은 하루에도 연 3% 금리로 이자가 붙습니다.
결국.. cma 통장의 고금리와 수시입출금 가능이라는 조건을 활용하여
언제 필요할지 모르는 목돈을 넣어두는 비상금 통장이 가장 적합하다는 결론이 나옵니다.
자.. 그러면 cma 통장은 어디서 가입해야 하고, 어떤 것들을 준비해야 할까요?
증권사 홈페이지에서 cma 통장을 보면 종류도 많던데.. 어려운 증권용어 같아서 머리가 아픈가요?
일단 cma 통장의 종류와 추천 유형에 대해서 공부해 보겠습니다.

 유형별 cma 통장의 종류
유형별 cma 통장의 종류
cma는 통장에 들어가는 돈이 어느 곳에 투자되는 곳에 의해 RP형, MMF형, MMW형 등으로 나뉩니다.
보통 이쯤에서 뭐가 이리 복잡해..?
그냥 금리비교나 해서 더 높은 금리의 cma에 가입해야겠다. 라고 생각하기 쉽지요.
그러나 유형별로 특징이 조금씩 다르니 간단하게나마 파악하는 것은
몸에 꼭 맞는 CMA통장을 고르기 위해 필요합니다.
1. RP(환매조건부채권)형 CMA
A등급 이상의 국공채, 회사채에 투자하며, 확정금리가 지급됩니다.
CP란 일정 기간이 경과한 뒤 일정한 가격으로 매수를 하거나 매도하는 조건으로 거래되는 환매조건부 채권입니다.
단기 투자자산이며 안전자산으로 분류된다는 특징이 있습니다.
그러나 RP에 직접 투자를 하려면 매도 후에 자금을 찾을 수 있고
업무시간 외에 출금이 제한되는 등의 불편사항이 있는데요,
RP형 CMA에는 이 같은 제약이 없어서 투자자들이 cma의 인기가 급증하게 된 것입니다.
2. MMF(머니마켓펀드)형 CMA
MMF(머니마켓펀드)는 단기채권, 기업어음, 양도성예금증서(CD) 등의 단기자산에 투자하는 펀드입니다.
MMF 역시 개별 상품으로 매매가 가능합니다.
그러나 RP와 마찬가지로 접근과 출금 등의 제약이 있는데, CMA는 그런게 없지요.
3. MMW형 CMA
MMW(머니마켓랩)은 한국 증권금융의 예금에 투자하는 랩상품 입니다.
현재 타 유형에 비해서 조금 더 높은 금리가 제공되어서 인기가 있습니다.
AAA등급 이상의 예금과 채권 등에 투자하여 운용하기 때문에 안전성도 높습니다.
금리가 시장에 연동되고 일복리로 계산되므로 장기간 cma에 자금을 넣어둔다면 유리합니다.
즉.. 언제빼서 쓰게 될지 구체적인 계획이 없는 비상금 통장에 적합할 수 있겠지요..
허나 확정금리로 이자를 받고자 한다면 rp형 등의 cma 통장을 추천합니다.

 판매 기관별 cma 통장 종류
판매 기관별 cma 통장 종류
cma의 유형과 별개로, cma 통장을 어디서 취급하느냐에 따라 cma통장의 특징이 구분지어지기도 합니다.
cma를 판매하는 곳은 증권사와 종합금융회사 두 곳이 있습니다.
은행에서도 cma를 판매하는걸 보게 되는데, 이 경우는 대행업무이고
직접적으로 은행이 cma를 판매하고 취급하지는 않다는 것 주의하시고요..
1. 증권사 cma 통장
대부분의 cma통장은 바로 이 증권사에서 판매하는 cma입니다.
왜냐? 종합금융회사 보다 증권회사의 수가 더 많고 상품의 종류도 다양하니까요.
증권사의 cma는 예금자보호가 되지 않습니다.
그러나 위에 설명한 대로 대체로 안전자산에 투자를 하기 때문에 원금손실에 대한
리스크는 거의 없다고 보면 됩니다. 그러나 아무래도 사람 기분이라는게 있는 만큼..
예금자보호가 되지 않는다는 점은 증권사 cma의 결정적인 약점 중 하나 입니다.
2. 종합금융회사(종금사) cma 통장
종합금융회사는 은행의 고유업무를 제외한.. 각종 금융업무를 볼 수 있는 곳입니다.
보험, 대출, 지급결제 등을 제외하고 대부분의 금융활동이 가능한데요.
종합금융회사는 일종의 특혜를 입고 있는바.. cma통장도 특별합니다.
바로.. 일반 은행의 예적금 상품과 마찬가지로 5천만원 한도의 예금자보호가 된다는 사실.
아쉽게도 종합금융회사의 수가 많지 않지만,
100% 안전한 자산이기 때문에 많은 분들이 종금사의 cma 통장을 선호합니다.
그리고.. 그 인기를 방증하듯, 종금사의 cma 금리가 증권사에 비해 상대적으로 높습니다.

 이자계산방법에 따른 CMA 통장 종류
이자계산방법에 따른 CMA 통장 종류
cma 통장은 돈이 어떤 순서로 들어가고 나가느냐에 따라 또다시 분류가 가능합니다.
즉.. 먼저 들어간 돈이 먼저 나가는 선입선출과, 나중에 들어간 돈이 먼저 나가는 후입선출.
이 두 방식으로 구분이 되는데요. 이것에 따라 이자 계산이 상당히 달라진답니다.
1. 선입선출식 CMA 통장
대부분의 CMA 통장은 선입선출식입니다. 은행 예금들도 마찬가지인데요..
만약 선입선출식 CMA에 가입한 사람이 다음과 같은 순서로 돈을 넣고 뺐다고 가정한다면..
1월 1일 : 200만원 입금
2월 1일 : 100만원 입금
3월 1 일 : 100만원 출금
5월 1일 : 현재 날짜(가정)
즉 1월과 2월에 각기 200만원, 100만원씩 입금을 하고 한달 뒤인 3월에 100만원을 출금하였습니다.
이 때 3월 1일에 출금한 100만원은 선입선출식에 따라..
1월 1일에 입금한 200만원 중에서 100만원이 빠져나간 것이 되겠지요.
그러므로 CMA 통장에 들어간 예치금에 붙는 이자 계산은 다음과 같습니다.
1월 1일 200만원 입금 금액 중에서
1) 100만원에 대해서는 (3월 1일에 출금된 100만원) 1월 1일부터 2월 28일까지 이자가 붙음
2) 100만원에 대해서는 (3월 1일 출금 후에도 계속 남은 100만원) 1월 1일부터 5월 1일까지 이자가 붙음2월 1일 100만원 입금액은 2월 1일부터 5월 1일까지 이자가 붙음
돈을 찾는 시점부터 1월 1일에 입금한 돈 중에서 100만원은 이자지급이 뚝 끊겨버립니다.
이자라는 것은.. 예치기간과 동일한 비율로 붙으므로.. 오래 넣어두면 좋습니다.
100만원을 인출하고 곧바로 100만원을 입금하더라도 그냥 놔둔거에 비하면 이자 손해를 볼 수 밖에 없습니다.
이것이 선입선출식 cma 통장의 단점인데.. 그러므로,
선입선출식 cma 통장에 돈을 넣어두면
어지간한 일이 생기지 않는 이상 돈을 뺐다가 넣는 것을 반복하지 않는 것이 좋습니다.
자주 출금을 할수록 가장 먼저 입금한 돈이 순서대로 빠져나오니까요.
2. 후입선출식 cma 통장
후입선출, 즉 나중에 들어간 돈이 먼저 빠지는 방식입니다.
돈을 수시로 입금, 출금을 해도 이자 손해를 보지 않는다는 것이 장점입니다.
위의 예로 든 경우에도 3월 1일에 100만원을 출금하면 2월 1일에 입금한 100만원이
빠져나오므로.. 선입선출식에 비해서 총 이자가 더 많이 붙는 것 입니다.
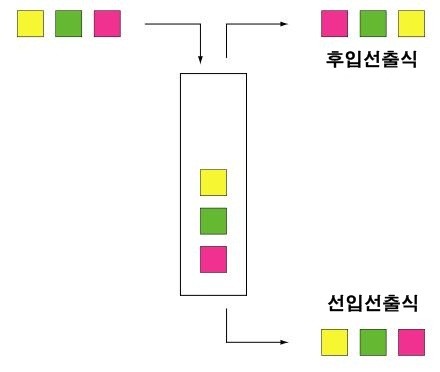
[선입선출과 후입선출 개념도]
그러므로.. 누구나 cma 통장은 가능하면 후입선출식으로 가입하는게 좋은데요
안타깝게도 현재 판매되고 있는 cma통장 중에서 후입선출 방식은 금호종금의 cma가 유일합니다.
종금? 종합금융회사 cma라서 기분 좋게 가입을 하려고 하지만~
몇가지 아쉬운 점이 있습니다.
1) 취급 지점이 많지가 않아서 불편할 소지가 있다는 단점
2) 사용시간에 제약이 있다는 단점
금호종금은 광주본사, 서울지점(을지로), 강남지점, 목포지점.
이렇게 네개의 지점이 전부 입니다. 많은 분들이 통장 개설 자체가 힘든 조건이지요!
그리고.. 24시간 이용이 가능한 증권사와 00:30~23:30까지 이용가능한 메리츠종금에 비해
사용시간에 제약이 있습니다. (07:00 ~ 22:00)
그러나 사용시간 제약은 비상금 통장으로만 사용하면 큰 문제가 없다고 보면 됩니다.
아무튼 지금 설명한 두가지 단점 외에는 금리도 높고(아래에 cma통장 금리비교 확인)
후입선출식이라서 이자 걱정 없이 입출금을 할 수 있다는 막강한 장점이 있습니다.
그리고 종합금융회사의 cma통장이므로 예치금 5천만원 내에서 예금자보호까지 된답니다.
'재테크' 카테고리의 다른 글
| 고 배당금 주식 (0) | 2015.11.26 |
|---|---|
| ISA (종합자산관리계좌) (0) | 2015.11.18 |
| 주택청약저축 (2) | 2015.11.18 |
| 증권사 CMA주식계좌들의 차이점 (펌) (0) | 2013.12.03 |
| [정기예금/적금] 비과세 + 고금리 상호금융 저축 (0) | 2013.08.17 |
| 보너스- 암 보험 팁 (0) | 2011.05.11 |
| 20, 30, 40대 재테크 그리고 현재의 나 (0) | 2011.05.11 |
| 의료실비보험(실손보험) (0) | 2011.05.11 |
| 연금저축보험 팁 (0) | 2011.05.11 |
| 변액유니버셜보험 장단점 (4) | 2011.05.11 |